Recent progress and challenges in analyzing complex astrophysical spectra
The sensitivity of recent (Herschel/HIFI, ALMA, JVLA) and future (SKA, ngVLA) astrophysical instruments has brought on a plethora of observations of very rich spectra in a variety of object classes: stellar envelopes, hot cores, hot corinos, but also shocked regions. Extracting all the information in a timely manner has been a challenge, particularly if one goes from more traditional single spectra to spectral cubes.
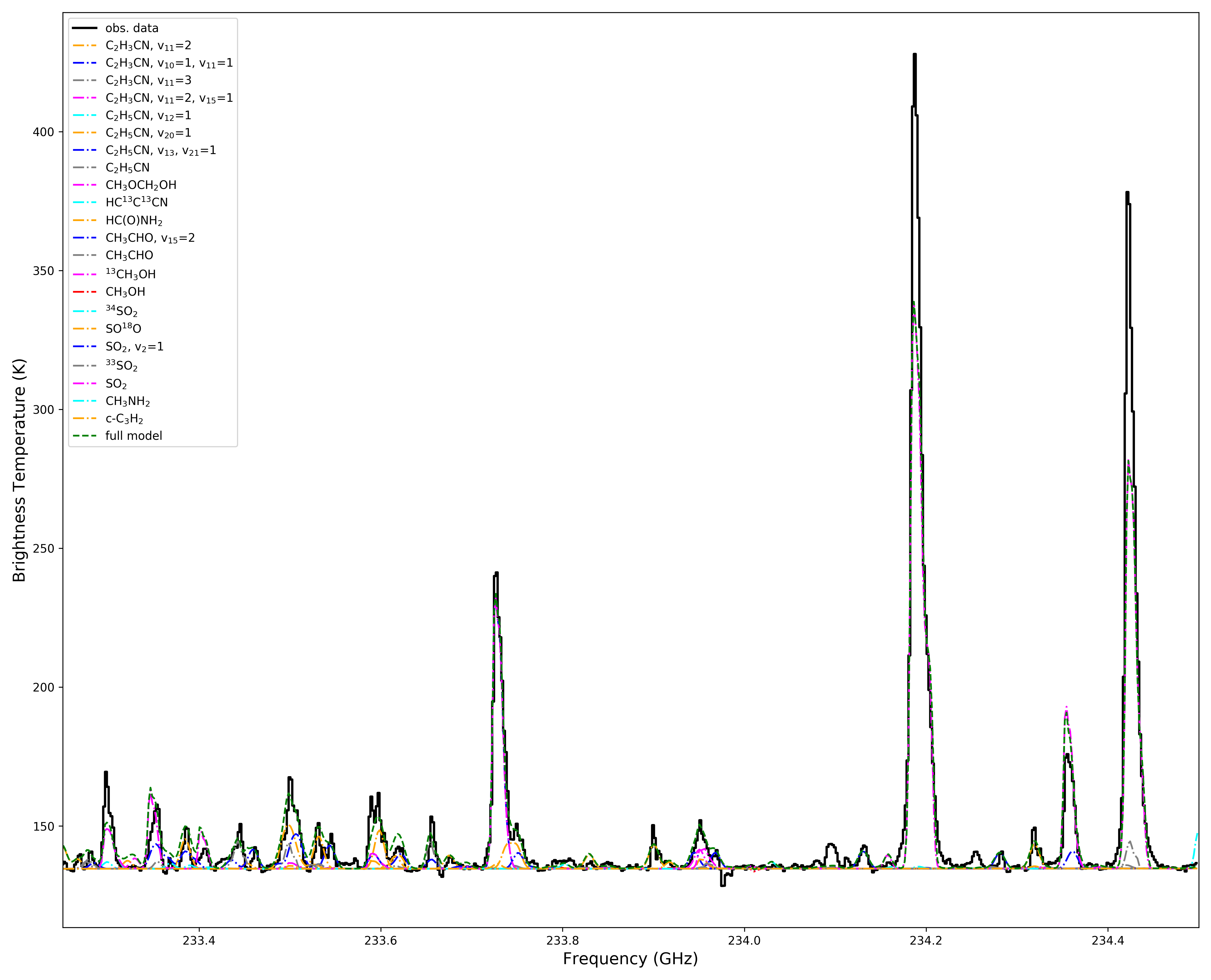
We identify the following main challenges:
- Line blending: if one wants to identify and characterize single species, one cannot do that in isolation, but has to identify all species to be sure one understands the overlaps and does not misidentify species,
- Excitation conditions: line blending can also severely hamper the ability to determine source parameters such as temperatures, if line blendings are not identified or corrected for,
- Non-LTE conditions: most line fits are done under the LTE assumption, partly because it is justified in many cases because of high densities, partly out of necessity, since collision rates for many species do not exist, or are restricted to a rather small basis set and/or narrow temperature range,
- Source structure: most fitting methods assume one or at best a few components that may or may not interact, this often is a rather crude approximation of the complex density and temperature structure of real sources,
- Molecular Line Catalogs: although this is left as the last point of the list, their incompleteness often is the dominant source of uncertainty in fitting. This has two aspects: looking for new species with (in most cases) weak lines requires a good understanding of all the other lines, and excitation studies, particularly close to the exciting sources, require the knowledge of highly excited lines, often of vibrationally excited levels, including of isotopologues, that often doe not exist.
While the first four points can be dealt with to some degree with new and better modeling approaches (e.g. XCLASS https://xclass.astro.uni-koeln.de/) and implementing novel concepts drawn from Machine Learning methods (although they are ultimately limited by the fact that constraining the true 3-d structure from observations will not always be possible), the last point requires more and better molecular catalogue entries, probably also requiring new methods of data acquisition and analysis.